Incident Milestones
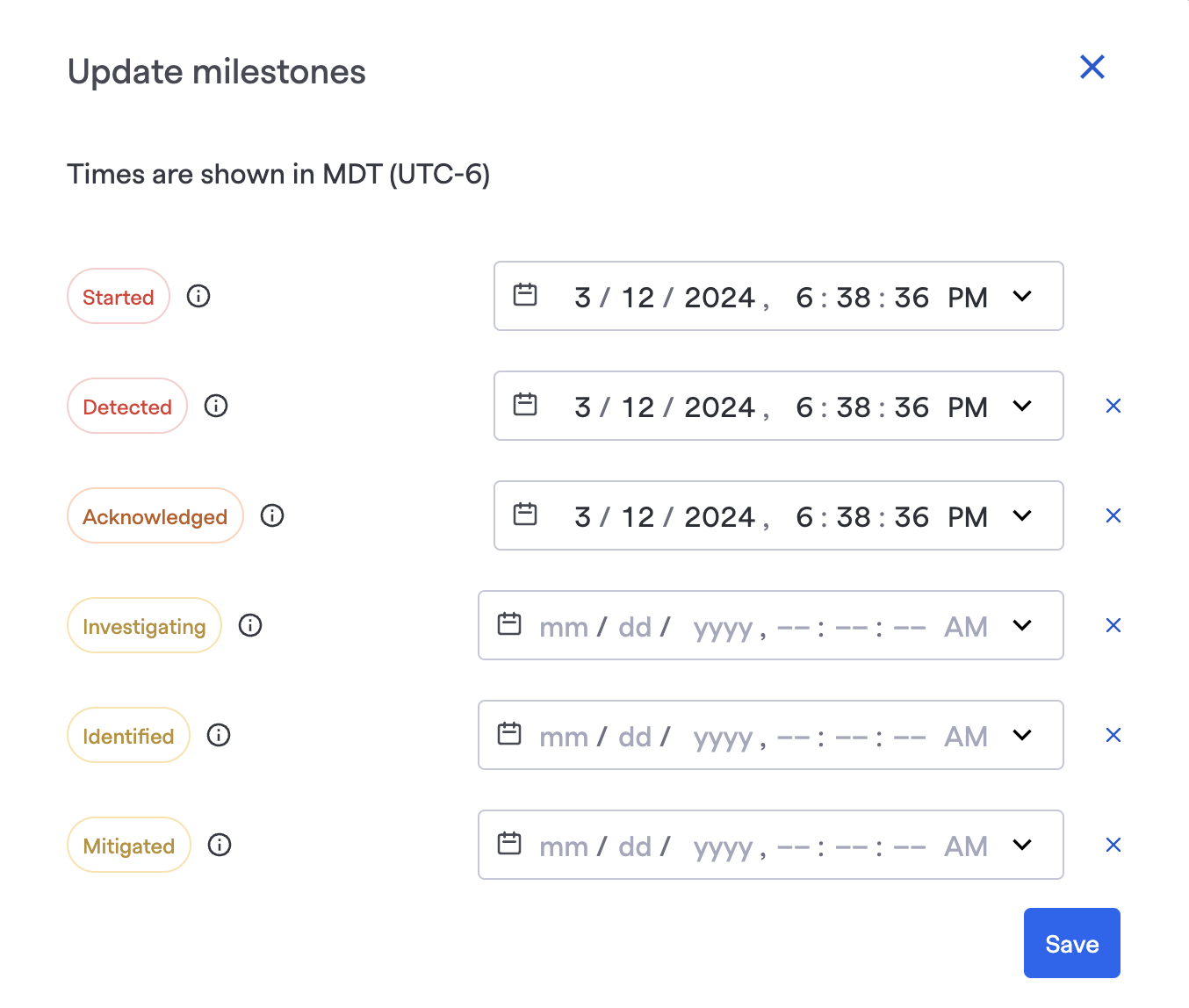
Updating Milestone times in the UI
Milestones describe the current status of the incident and communicate to stakeholders the team's progress in resolving the issue. As responders work through incidents on FireHydrant, they will typically transition the Milestone, and FireHydrant automatically logs the timestamps of these changes.
This allows FireHydrant to collect data for holistic incident metrics out-of-the-box like MTT*, Impacted Infrastructure, Responder Impact, and so on.
Milestone timestamps can be adjusted during the incident in Slack (using /fh update) or within the FireHydrant UI can also be changed post-incident during the Retrospective phase.
Note:
The milestones must be chronologically equal to or greater than the previous. For example, the Acknowledged milestone cannot be earlier than the Started milestone.
Default Milestones
FireHydrant comes with several incident milestones out of the box. We established these as basic guidelines for organizations that are either new to incident management or looking for guidance on best practices.
Started

Started milestone
When the affected system began having problems.
By default, this is set when an incident is opened in FireHydrant. We use this timestamp to calculate the time difference to the rest of the milestones.
You can modify this timestamp if the incident started before opening the FireHydrant incident.
Detected

Detected milestone
When a monitoring system (or human) noticed that the system was having problems.
If you open a FireHydrant incident directly from an inbound alert, this milestone will be set to the timestamp of the alert. When this happens, the Started milestone will also be set to the same timestamp.
If you open an incident without an attached alert, this milestone will remain unpopulated and must be manually set.
Acknowledged

Acknowledged milestone
When someone responding to the incident acknowledged the situation.
If you manually kick off a FireHydrant incident, the incident starts in this state, and the Started milestone’s time will match it. If the FireHydrant incident was started automatically (e.g. via API or Alert Routing), then you will need to manually transition to this state.
Investigating

Investigating milestone
When the first concrete step toward triaging and identifying the problem was taken.
You must transition to this milestone manually.
Identified

Identified milestone
When the problem was identified and corrective actions began.
You must transition to this milestone manually.
Mitigated

Mitigated milestone
When the system is no longer exhibiting problems to users, but the team is still monitoring the situation.
For example, the team may be waiting to see if signals or SLIs normalize after the corrective action, or maybe the team took temporary corrective measures to stop customer impact, but a more permanent fix is needed before the incident is considered resolved.
You must transition to this milestone manually. If you transition to Resolved state and skip this milestone, it will automatically be filled with the same timestamp as Resolved.
Resolved

Resolved milestone
When the system is confirmed to be working again with no relapse.
This is also the time when temporary fixes to mitigate the issue are removed, and the system is now behaving as normal.
You must transition to this milestone manually.
Retrospective Started

Retrospective Started milestone
When the team has begun the retrospective for an incident.
The incident will transition to this milestone when you click "Start Retrospective" in the Command Center or if you run /fh start retro in Slack.
This milestone is tracked and only shown/modifiable in the interface after the incident has been Resolved.
Retrospective Completed

Retrospective Complete milestone
When the team has finished reviewing the incident, clarified learnings and follow-ups, and published findings.
The incident will transition to this milestone when you click "Publish Retrospective" on the Retrospective page.
This milestone is tracked and only shown/modifiable in the interface after the incident has been Resolved.
Updating Milestone Times
When you transition a Milestone, the timestamp at which you performed the action is filled in. However, you can change these values at any point.
You can change the values by clicking the Milestone dropdown in an incident's Command Center:
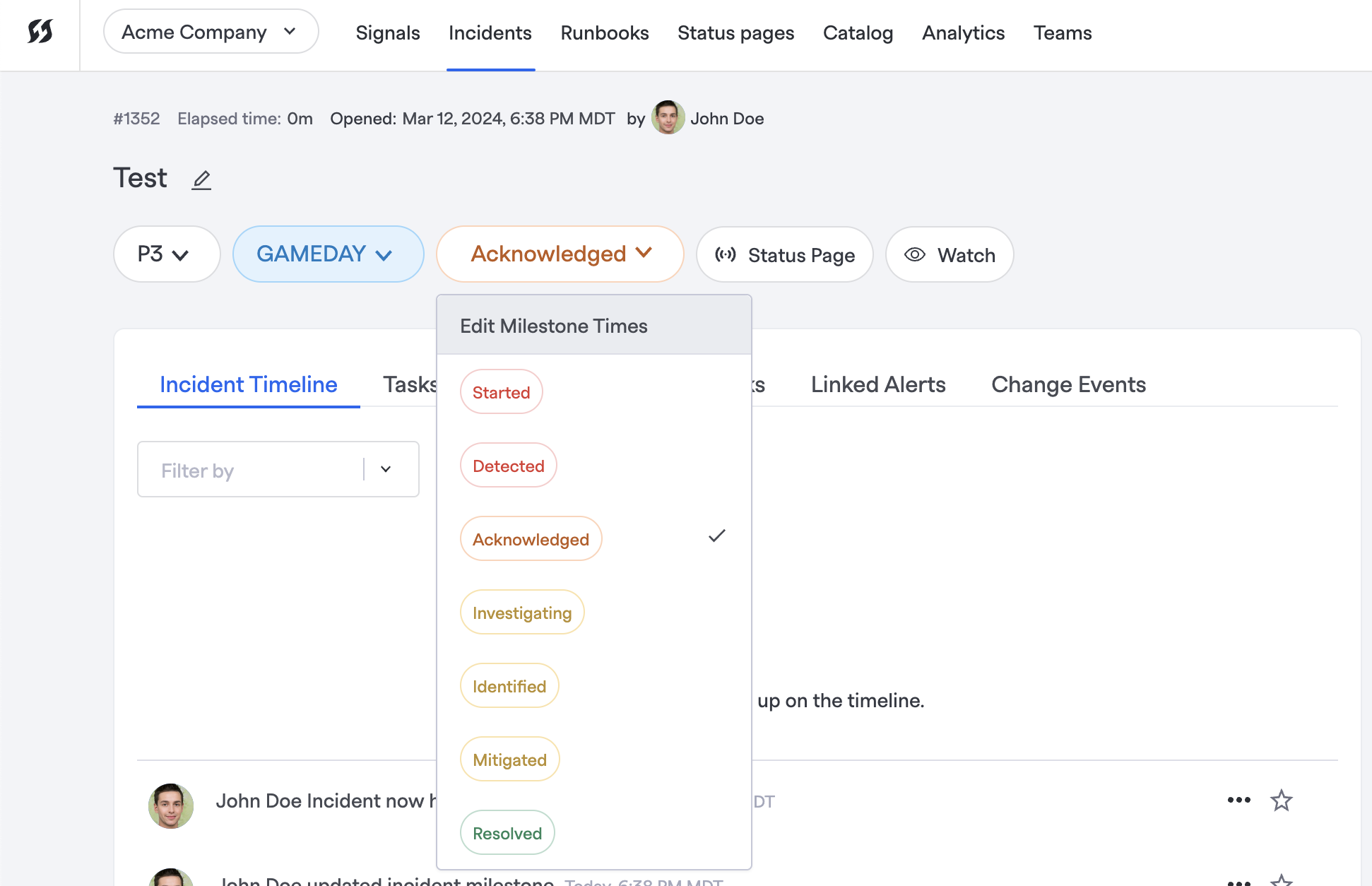
Editing the milestone timestamps via Milestone dropdown
Alternatively, you can go to any event in the timeline, click the ellipses, and then use that particular event's timestamp as a value for a chosen milestone. For example:
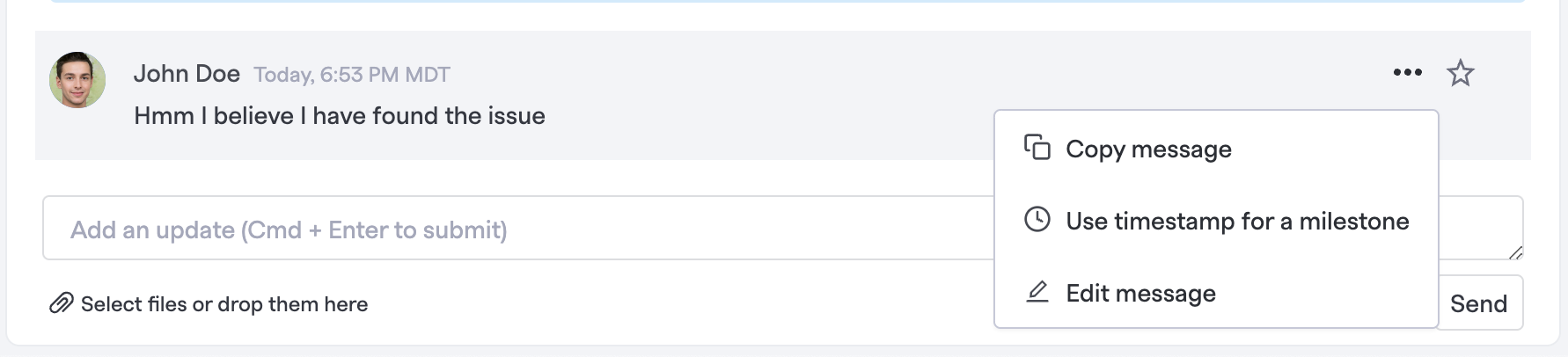
"Use timestamp for a milestone" will take the timestamp of this timeline item and set it to the milestone you choose.
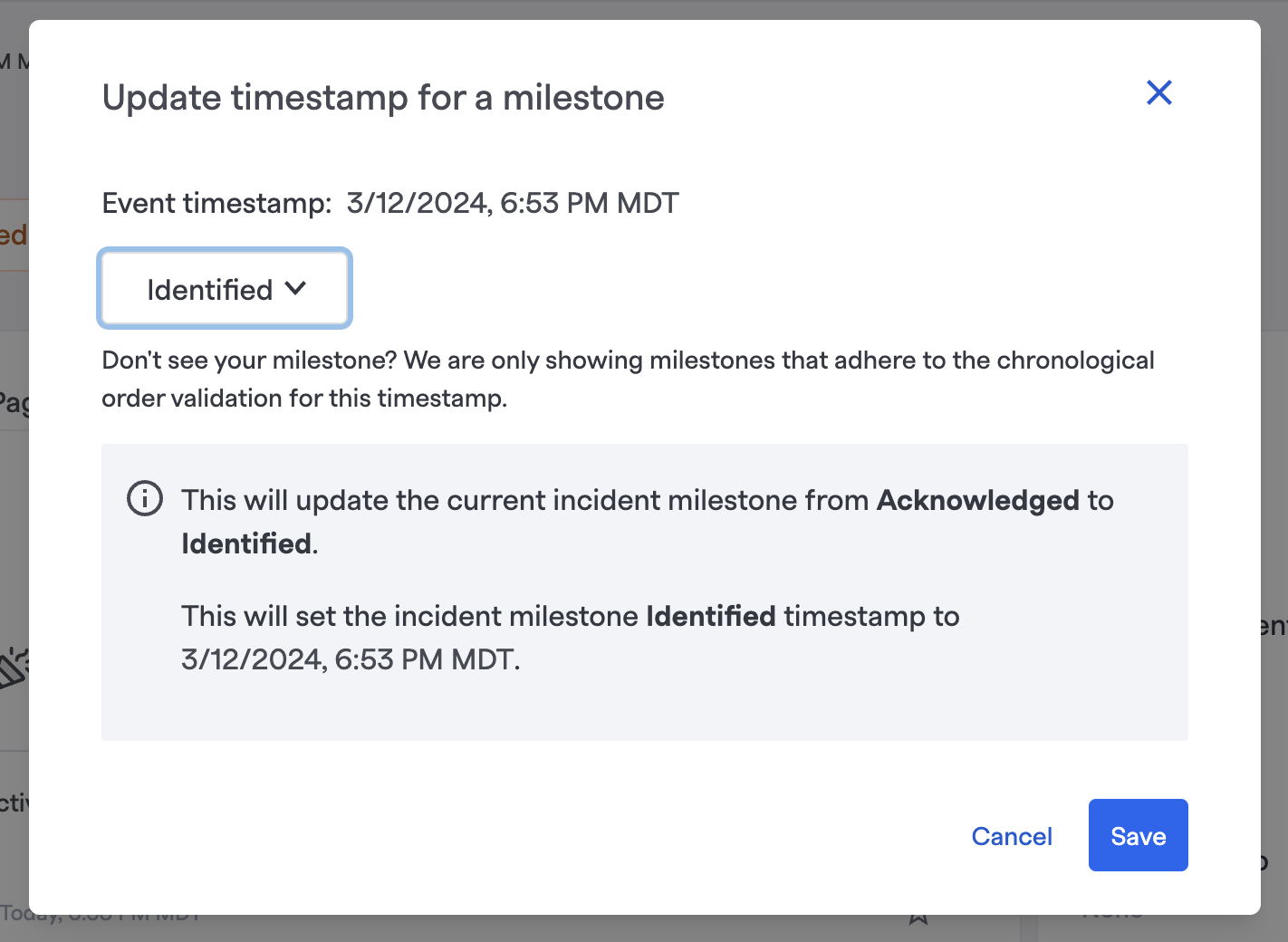
In this example, we set the "Identified" milestone to the timestamp that John Doe mentioned he found the issue
Incident Metrics
Incident metrics are crucial for helping you understand the health and effectiveness of your services, environments, functionalities, and incident response teams. They can help determine how quickly your organization is responding to incidents, and in turn, how much trust you are building with users.
Luckily, FireHydrant can provide you with the information you need to make informed business decisions when it comes to reliability.
The following metrics are built from the Milestone timestamps:
- MTTD : Mean Time to Detection
time of detection - time of incident start - MTTA : Mean Time to Acknowledged
time to acknowledgment - time of incident start - MTTM : Mean Time to Mitigation
time to mitigation - time of incident start - MTTR : Mean Time to Resolution
time to resolution - time of incident start - Healthiness :
(MTTM * incidents) / time window- As an example, if you have an incident for a given service that was started at noon, mitigated at 1 PM, and then resolved at 2 PM, healthiness for that infrastructure would be 50% for the window of noon to 2 PM.
- Impact : Within a given date range, multiple incidents are added up to calculate the time a service, functionality, or environment was degraded.
Next Steps
With a basic understanding of FireHydrant's incidents, dive into the details of conducting one by visiting the following pages:
Updated about 2 months ago